Proyecto conacyt
Reconocimiento de imágenes predeterminadas por un robot en movimiento.
Objetivo
Introducción
Desarrollo
Conclusiones
Creación de un sistema computacional instalable en un robot con la capacidad de captura de video cuadro por cuadro que le permita al robot encontrar objetos de manera autónoma y sin asistencia, teniendo un entrenamiento previo donde el robot se expone a los objetos que desea encontrar.
El sistema busca imágenes planas pegadas a la pared de un cuarto únicamente con figuras muy sencillas (actualmente flechas con diferentes direcciones y círculos) en una combinación limitada de colores (3 colores en total actualmente).
![]()
![]()
El reto principal en esta parte del desarrollo es la elaboración de un algoritmo que pueda diferenciar de manera certera entre un círculo y una flecha; y entre las diferentes direcciones de las flechas.
Se han probado diferentes aproximaciones a la resolución del problema; tanto en preprocesamiento como en procesamiento.
Se consideran las siguientes variaciones de la fuente:
- Variación de luz
- Ruido ambiental
- Variación de escala
- Variación de distancia
- Perspectiva
Se esta trabajando en
- Rotación a ángulos pequeños
- Rotación a ángulos grandes
El método para considerar variaciones de luz es mediante la programación de colores; enseñando a la computadora como se ve un mismo color en diferentes iluminaciones tal que la computadora pueda por si sola asumir que se trata del mismo color en el futuro.
Para convertir los colores se clasifican en dos categorías mayores: Colores conocidos y desconocidos. Cualquier color desconocido es transformado a blanco o negro; y para fines de cualquier cálculo es ignorado.
Para los colores conocidos, se calcula a que color r se asemeja más un color de la imagen fuente dado y se convierte al color conocido al que coincidió.
Para determinar si un color es conocido o no; y cual conocido es se utiliza distancia de color y una tabla de índices en la cual se especifican diferentes colores que representan el mismo color. Por ejemplo, el color rojo se puede representar como 255, 0, 0; una tabla para el rojo podría verse como:
|
255,0,0 |
255,0,0 |
|
255,10,8 |
255,0,0 |
|
238,1,2 |
255,0,0 |
|
249,30,10 |
255,0,0 |
|
249,1,3 |
255,0,0 |
En la etapa de preparación, se procesan varias imágenes con diferentes iluminaciones y colores por cada uno de los colores conocidos y, manualmente, se buscan errores de color, tales como colores confundidos o no considerados, luego de lo que se captura el color de los errores y se agrega a la tabla para el color correcto.
El ruido producido por la captura y el ambiente suele provocar ligeras variaciones de color, causando que la imagen se vea granosa. Dichas variaciones se eliminan completamente con el proceso de binarizacion descrito en "Variación de Luz"
Los patrones que busca el robot siempre son rectángulos de un color conocido, con un patrón de otro color conocido, siempre con las mismas proporciones.
Cuando se encuentra un candidato de patrón, lo pimero que se hace es cambiar el tamaño a uno fijo.
Ya que las proporciones del rectángulo son fijas, al ajustar la escala de todo el patrón, se garantiza de una manera bastante certera que l aparte interior siempre tenga el mismo tamaño.
La variación de distancia es solo un caso de variación de escala.
El efecto causado por la perspectiva ocasiona que las caras superior e inferior del marco no se vean paralelos, por lo que hay una cara lateral más grande que la otra.
En general, con la perspectiva toda la imagen se va haciendo más pequeña con la distancia.
Para detectar ese problema, una vez que un candidato ha sido cambiado de escala se busca algun color desconocido en la parte superior e inferior del patrón, lo que significa que el lado no es perfectamente horizontal.
Para corregir el problema, la imagen se recorre línea por línea y el tamaño de cada línea se ajusta tal que no haya ningún color desconocido en la parte superior ni inferior de la misma.
En la primera etapa, el reconocimiento se hizo con un simple conteo de colores en la imagen por sectores. La división se hizo de la siguiente manera:
En cada uno de los fragmentos de la imagen se contaba el número de apariciones de cada color conocido.
Esta manera de atacar el problema resultó suficientemente efectiva. De todos los casos de prueba solo hubo un patrón mal clasificado, y se corrigió con entrenamiento adicional.
La razón por la que se busca otro método es porque este no escala, es empírico y difícil de adaptar para trabajo futuro como tolerancia a rotaciones mayores e incursión de nuevos patrones.
La propuesta actual consiste en encontrar una serie de puntos en la imagen que revelen si un patrón corresponde a una flecha o a un círculo; ademas de información adicional de la flecha como su orientación,
Los puntos a buscar son los siguientes:
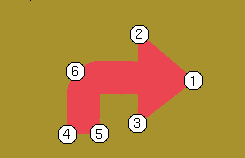
El método propuesto consiste en dividir la imagen en 4 cuadrantes como se muestra a continuación:

En este punto, la imagen debe tener dos colores conocidos y nada mas; uno de fondo y uno de frente, para esta parte del proceso el color es irrelevante, así que se descarta. El color de fondo se considera "no información" y el de frente "información".
Esto se hace contando el numero de apariciones de los colores conocidos en el patrón; y utilizando el segundo color mas frecuente como frente y lo demas como fondo.

A continuación se utiliza un método de asignarle pesos a las partes con información para tratar de encontrar los diferentes puntos en la imagen. Por ejemplo, para encontrar el punto 1 de la figura se asignan pesos que, gráficamente, se ven así:

El algoritmo para encontrar los pesos es muy sencillo, únicamente es una suma de x con y, considerando el origen en donde convenga para el punto en particular que se está buscando.
Finalmente, se descartan los puntos superior-derecho del cuadrante inferior-izquierdo, el superior-izquierdo del cuadrante inferior-derecho, el inferior-izquierdo del cuadrante superior-derecho y el inferior-derecho del cuadrante superior-izquierdo (o sea los cuatro puntos que invariablemente aaban en el centro) y el resto se pasa a una red neuronal, que hace la discriminacion del diferente tipo de flechas y circulos.
Existen 2 comandos principales en el programa; recognize y train.
El comando train es un shell script que primero llama al programa "ppm" para binarizar la imagen; despues llama a "extract" con el nombre de la imagen binarizada y el codigo del patron que va a extraer para obtener los puntos; y finalmente llama a "back3" que es la red neuronal para entrenarla.
El comando extract hace lo mismo, excepto que lo hace por cada archivo y al comando "extract" no pasa mas argumentos que la imagen binarizada.
El comando ppm recibe dos argumentos; la imagen de entrada y la de salida. Lo que hace es leer la imagen de entrada, reducir el numero de colores (binarizar) por medio de distancia de color y una tabla de colores cnocidos; y escribe el resultado en la imagen de salida.