Recognition of predefined images by a moving robot.
Objetictive
Introduction
Development
Conclusions
To create a computer system to be installed on a video capture capable robot that allows the robot to find objects autonomously; after receiving training where the robot exposes itself to the objects it will look for.
One primary goal is to make the system fast, so that it can process more frames in time and therefore preventing skipping important parts of the scene.
<...>
The system looks for flat images attached to a wall (posters). Currently the main goal of the system is to distinguish arrows (and their direction) and circles in combinations of 3 different colors..
![]()
![]()
The main challenge at this point is to create a system that can distinguish between circle and arrow, and the different directions of the arrows.
Several approaches have been tested, both in preprocessing and in processing.
The following variations have to be considered:
- Lighting
- Environmental noise
- Scale
- Distnce
- Perspective
Work is in progress for
- Small angles rotation
- Big angles rotation
The light variation problem is directly related to the color recognition problem.
The method used to identify colors was to teach the computer how known colors looked like under various lighting conditions, and then also teach it several "unknown" colors. Using color distance the computer can then recognite future appearances of the same color in the future.
To convert the colors two major categories are considered: Known and unknown colors. Unknown colors are transformed into black in the first stage of preprocessing, and it is further ignored for any calculations.
In the case of known colors it is measured what color in the registry in memory is most similar to it, and then it is replaced by this color in the image.
To determine if a color is known or known color distance is used against an index table, where different RGB values are specified that may represent the same color. For instance a table for red could look like:
|
255,0,0 |
255,0,0 |
|
255,10,8 |
255,0,0 |
|
238,1,2 |
255,0,0 |
|
249,30,10 |
255,0,0 |
|
249,1,3 |
255,0,0 |
In the preparation stage, several images are processed with similar light conditions to the expected ones and then, by hand, colors are picked and entered into the table. The images are processed several times with the new dat to look for errors of colors and then they're corrected by adding the original valuie that produced the error to the table mapping to the right color.
Image capturing, especially in dark places, usually adds noise to the image. This noise manifests in slight color variations, causing a plain surface to look bumpy. Because ths noise usually manifests itself in only slight variations the aforementioned tchnique to binarize the image usually deals with most of this noise. Typically enough for recognition, so no further measures are taken in this respect.
The patterns the robot looks for at this point are all rectangular posters of a fixed size. That helps develop a system that can completely eliminate the size variation caused by scaling
Before any kind of analysis, once a candidate pattern is found it's re-scaled to a fixed size considering it's outer bounds.
Since all the posters have the same proportions, once the pattern is re-scaled it is pretty much guaranteed that the inner pattern will always have the same size.
The effect that perspective causes in a rectangular image is to make the top and bottom sides to tend to collapse towards a point, therefore making the lateral sides be of different sizes.
In general, the image resizes down with distance.
To detect this error, black areas are looked for atop or bottom of a pattern after it's re-sized. If they are found it means the top and bottom of the image are not perfectly parallel. Once this is determined, the pattern is scanned with vertical lines, line by line, and each is resized so that the uppest part with information as well as the one that is lowest match the actual top and bottom of the pattern.
The first approach was to dividethe image into significant chunks and then to simple count the colors in each. The segmentation that proved to be the minimal, and yet satisfactory enough was:
The number of every known color in every fragment was counted and then handed to a neural network for recognition.
This approach turned to be effective enough. With training of just one sample image, all taken in perfect conditions, there was only one error in the test (and not perfectly conditioned) images. After adding that single image to the training set 100% accuracy was achieved.
The reason not to stay with this approach was because this approach didn't scale to more complex images, that could have all similar proportions of color in the different segments even habing different shapes; it wasted resources and inhibited good learning of the neural network, by giving it always one 0 in the color count for every segment (since the patterns only have a background and a foreground); furthermore, it was empirical and potentially error prone with images that required a big scaling up.
All the images, both training and test, were taken with a Canon Coolpix 990 camera, with the highest resolution (2048x1536). That is not the camera actually installed in the robot that is intended to be used.
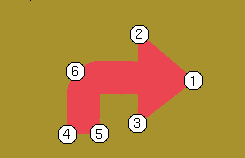
The current proposal is to find a set of points in the image that reveal relevant information about the patternenough to clearly distinguish in a color independent way what the shape is; so far circle or arrow.
The following points are the ones to be found:
In the proposed method, the image should be divided in 4 equal parts, like the following:

By this point the pattern should have no more than 2 colors, background and foreground; therefore color information beyond that is discarded, and now the image is converted to 1 bit.
This is done by counting occurrences of all known colors in the image. The most often color should be the background and the 2nd the foreground. So the 2nd most often color is converted to foreground, and the rest to background.

Then, to actually find the points, all the foreground of the image is weighted, in a way that could look like this, for a certain point:

The algorythm to find the weights is simple enough. It consists only of adding or substracting x and y in the given quarter of the image, depending on what point is being searched. Other alternatives were analyzed, such as multiplication, adding the square or square root of the values, but the simple add had the best results.
Finalmente, se descartan los puntos superior-derecho del cuadrante inferior-izquierdo, el superior-izquierdo del cuadrante inferior-derecho, el inferior-izquierdo del cuadrante superior-derecho y el inferior-derecho del cuadrante superior-izquierdo (o sea los cuatro puntos que invariablemente aaban en el centro) y el resto se pasa a una red neuronal, que hace la discriminacion del diferente tipo de flechas y circulos.
Existen 2 comandos principales en el programa; recognize y train.
El comando train es un shell script que primero llama al programa "ppm" para binarizar la imagen; despues llama a "extract" con el nombre de la imagen binarizada y el codigo del patron que va a extraer para obtener los puntos; y finalmente llama a "back3" que es la red neuronal para entrenarla.
El comando extract hace lo mismo, excepto que lo hace por cada archivo y al comando "extract" no pasa mas argumentos que la imagen binarizada.
El comando ppm recibe dos argumentos; la imagen de entrada y la de salida. Lo que hace es leer la imagen de entrada, reducir el numero de colores (binarizar) por medio de distancia de color y una tabla de colores cnocidos; y escribe el resultado en la imagen de salida.